|
|
Jump to navigation
Не секрет, что видеочипам стало тесно в узкой области обработки 3D и они все рьянее и рьянее рвутся в самые разнообразные сферы, доказывая силу концепции General Purpose GPU (многопоточных вычислений общего назначения на графических процессорах). Десктопным центральным процессорам все сложнее и сложнее оборонять от видеокарт свой кусок хлеба. Вот, и в такую исконно «центральнопроцессорную» вотчину, как кодирование видео, GPU запустили свои многочисленные руки уже по самый локоть. И если раньше в борьбе за кошелек пользователя центральные процессоры еще могли возмутиться: «А как же рендеринг и кодирование видео?!» - то сейчас и это уже не аргумент. Смотри сам.
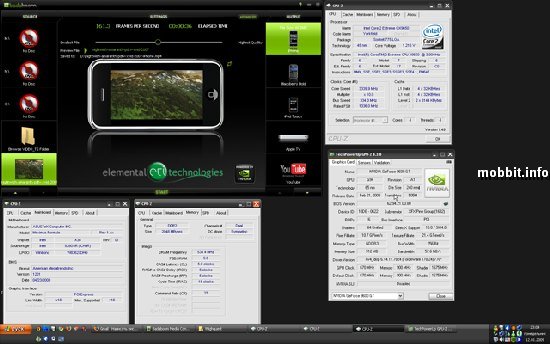
Кодирование видеоролика размером 100 Мб в формат MPEG2 для iPhone на топовом процессоре прошлого поколения Intel Core 2 Extreme QX9650 заняло 29 секунд (Внимание! Скриншоты кликабельны).
Кодирование того же ролика в тот же формат на Middle-End видеокарте прошлого поколения NVIDIA 9600 GT потребовало 36 секунд (продолжение - далее).
Интересная расстановка сил! Впрочем, оплакивать центральные процессоры не стоит – в топовых системах новым экстремальным процам всегда найдется место: кто ж еще сумет «раскачать» тандемы свеженьких двухчиповиков?
А мы тем временем не будем сопротивляться прогрессу и опробуем новые веяния, причем сделаем это с пользой для наших оверклокерских арсеналов. Погоняемся, господа!
Сегодня мы будем меряться длинам азотных стаканов в дисциплине кодирования видео… хмм… на видео :).
Предвосхищая недовольные вопли из зала, и чтобы каждый талантливый оверклокер, независимо от его материального достатка и доступного железа, мог конвертировать свое умение в новейшее железо, а также чтобы уйти от столь ненадежного ориентира, как цены на видеокарты, мы придумали хитрый ход: результат будет корректироваться в зависимости от количества конвейеров в чипах видеоподсистемы.
А теперь – призовой фонд:
1-е место – новейшая двухчиповая видеокарта NVIDIA GeForce GTX 295!
2-е место – мощный мидл NVIDIA GeForce GTX 260
3-е место – топ 9-й серии NVIDIA GeForce 9800GTX
Поощрительные призы:
4-е место - $150
5-е место - $100
Специальный приз – азотный стакан [DeDaL] Mirror-Pot на видео.
Что нужно делать?
Конечно же, как следует разогнать свою систему!
Кодировать будем ролик с музыкальным видео. Нам, вот, понравился клип Nightwish весом в 100 Мб.
Для кодирования будет использоваться следующее программное обеспечение из комплекта NVIDIA Power Pack
1. Badaboom
Выбираем файл;
Кодируем в формат для iPhone;
По завершении работы получаем страничку с fps и временем.
Скрин оформляем в соответствии с этим примером:
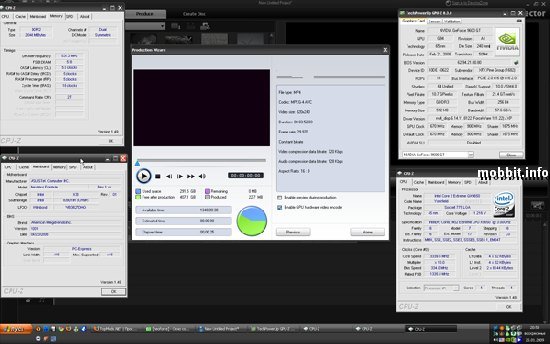
2. Power Director
Качаем Power Director с поддержкой CUDA отсюда
Удаляем то, что есть в демо, выбираем видео-файл, далее перетаскиваем вниз на линейку и жмем Produce.
Настройки кодирования:
Шаг 1 - Create file
Шаг 2 - Portable .MPEG4, настройки по дефолту
Шаг 3 – Start Rendering
В результате нас интересует параметр Elapsed time.
Скрин оформляется в соответствии с этим примером:
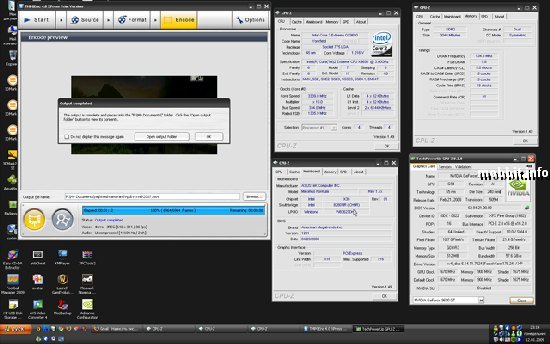
3. TMPEnc (требуется подключение к Интернету)
Перед запуском нужно подключиться к Интернету для активации триал лицензии.
В начале прога просит включить CUDA - включаем и рестартим программу;
Идем в меню Source и выбираем файл;
Смотрим инфо, кликаем ОК;
Затем идем в Format и выбираем Quick Time (MOV);
Затем Encode - Start Encode.
На выходе необходимо получить вот такой скрин:
Подсчет баллов
В первом тесте мы имеем fps и время, второй и третий – дают только время. Во всех трех тестах будем использовать показатель времени в секундах. Объем клипа является константой. Разделив объем клипа на секунды, мы получим скорость кодирования клипа в байт/сек. Складываем показатели скорости кодирования (байт/сек) во всех трех тестах. Полученную сумму делим на суммарное количество конвейеров (шейдерных процессоров) в видеоподсистеме. То есть, если это SLI или GeForce 9800 GX2, то количество конвейеров считается в двух чипах, а если это 3-Way-SLI, то в трех.
Формула расчета выглядит следующим образом:
R = (V/T1 + V/T2 + V/T3) / QP, где
R – результат участника,
V – объем файла в байтах,
T1, T2, T3 – время кодирования видеоролика в 1-м, 2-м и 3-м тестах, соответственно,
QP – суммарное количество конвейеров (шейдерных процессоров) в видеоподсистеме бенч-стенда.
Специальный приз, независимо от других выигранных призов, получает участник, набравший минимальное суммарное время кодирования видео по итогам всех трех тестов: (T1 + T2 + T3) -> min
Судить конкурс будет судья международного класса, резалт-модератор рейтинга www.hwbot.org, опытный оверклокер и просто хороший человек NeoForce.
Рейтинг участников будет обновляться по мере поступления заявок.
Срок приема результатов на конкурс: с 00:00:00 26.01.2009 по 23:59:59 11.02.2009.
Организаторы оставляют за собой право обрабатывать результаты, получать разъяснения от участников, требовать провести повторные замеры производительности, предоставить видеоподтверждение и другие доказательства реальности результата в течение срока, необходимого для полноценной и справедливой оценки и проверки результатов.
Пересылка призов осуществляется за счет организаторов. Немедленная отправка приза после публикации итого конкурса не гарантируется. Приветствуется альтернативные пути получения приза: например, через знакомых, находящихся проездом в Москве.
Денежные призы переводятся в рублях почтовым или банковским переводом на имя, адрес или банковский счет призера.
Обсуждение и прием результатов – здесь
27.01.09
 Всего голосов: 10 - Рейтинг: 4.90 Просмотров: 13074
Понравился пост "Видео – картам! Конкурс оверклокерского кодирования видео"?
Поделись с друзьями:
Я в принципе, мало, что смыслю в этм посте, но постараюсь все таки понять.
NVidia похоже совсем в глубокой жопе, что на такой примитивный пиар пошла. ATI рулит!!!
Archetype , есть извилины в тыкве мля ? походу ниасилил о чем статья , ппц ........ поиграте в Mirror`s Edge школьники-фанаты
ATI ;))
Будем сдержаны, товарищи. Если ты про PhysX, то это не показатель: у AMD есть движок Havok, который вполне можно сопоставить. (если что, то у меня NVidia ;) )
Мдя, на сколько я понимаю гпу заточены под спецефические математические задачи: тресировка и рендеринг и т.п. Я не видел схем гпу и мне впадлу искать их и смотреть, но не думаю, что в них реализована и половина инструкций нормального риск камня. Следовательно их будут имитировать за множество циклов со всеми вытекающими. Ну и если им воткнется вводить новые инструкции, то это обернеться повышением цен, в то время как основные графические характеристики расти не будут.
а на моей квадре CUDA нету(( всех бы порвал
Добавить комментарий
Комментарии, содержащие мат, будут удаляться
Войти! | Регистрация | Напомнить пароль
|
|
|